Vue3를 Composition API 스타일로 쓰는 연습 중이다. Composition API에서 새로 도입된 타입이 있다. ref() 함수로 정의하는 리액티브 타입이다. ref() 함수로 리액티브 변수를 정의해서 console.log()를 찍어보면 Proxy 라는 낯선 이름이 보인다. Proxy란 무엇일까?
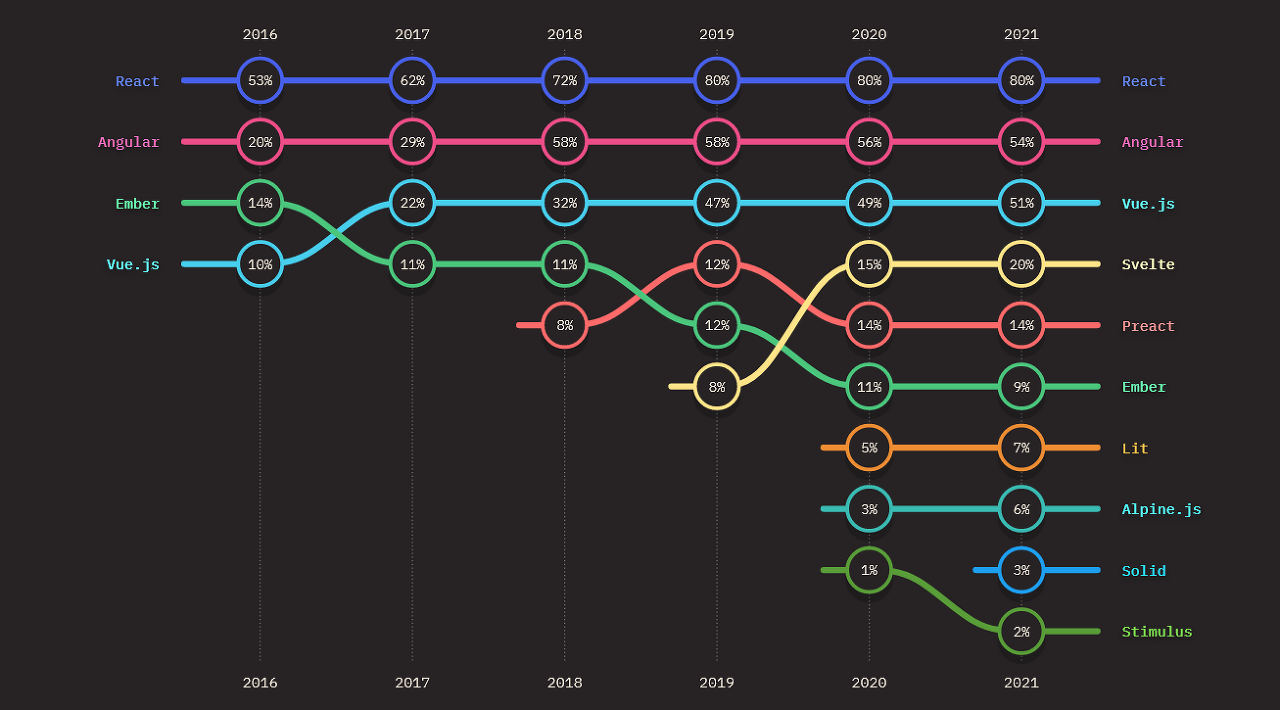
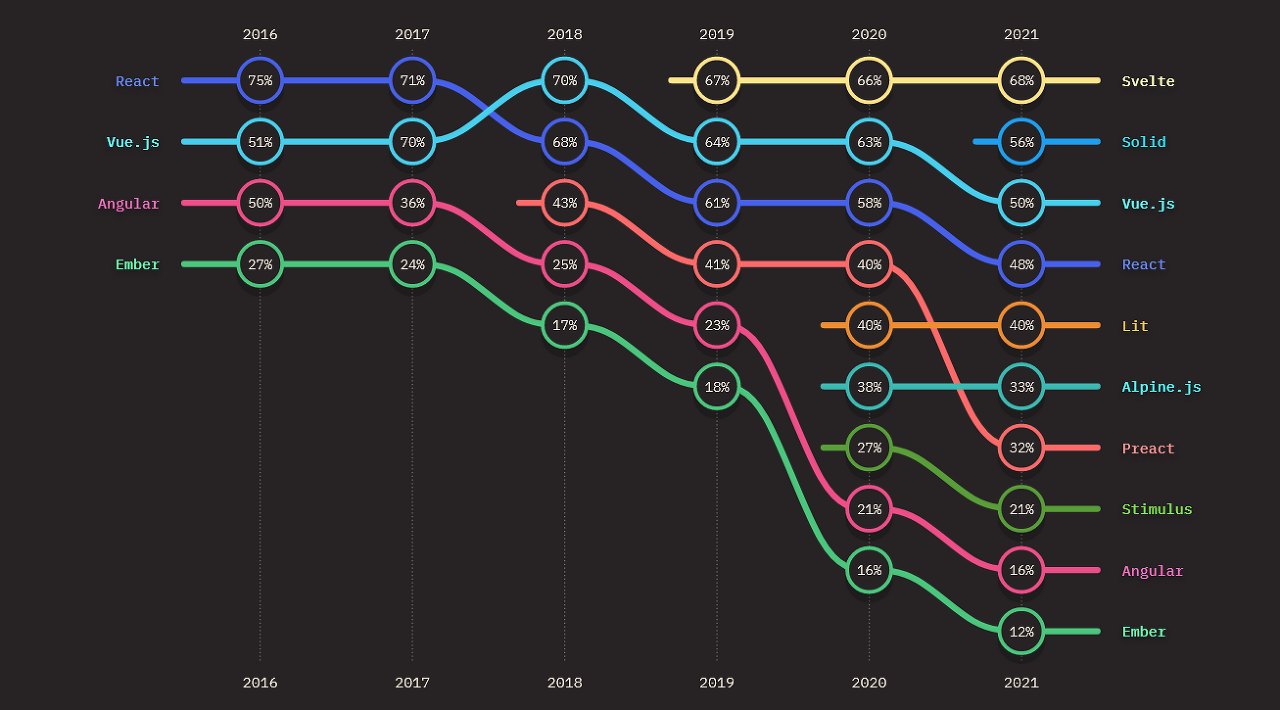
2023-02-12 회고: Vue는 당분간 괜찮은 위치를 유지할 것 같다. 2022년 연말에 새로 발표된 설문 결과에서도 관심있는 프레임워크 3위, 많이 쓰는 프레임워크 3위 자리를 유지했다. 무엇보다 커뮤니티 활동이 활발하고 합리적인 것이 마음에 든다. 정체되어 있지 않고 꾸준히 발전하는 느낌이다.
Vue2 vs Vue3 뭘 선택해야 하나?
Vue 히스토리 : 2014년 첫 출시, 2020년 Vue3 출시
Vue3의 목표는...
도구의 처리 속도를 빠르게 하는 것
코딩 방식을 단순하고 직관적으로 만드는 것
Vue3에서 달라진 점
Vite/빗 기반 툴체인 혁신
Composition API 스타일 도입 (복잡한 코드일수록 더 간결하게 관리)
Teleport API 제공 (컴포넌트를 더 유연하게 재활용)
앱 성능 개선 (메모리 사용량 133% 개선, 번들 크기 41% 절약)
2022-11-07 선택: Vue3를 쓰자 - 지금 안 배우면 언제 배울까?
2023-02-12 회고: 새로 시작하는 프로젝트여서 익숙한 Vue2 대신 Vue3를 선택했는데, 잘한 선택이었다. Vue3에 새로 도입된 <script setup> 태그와 Composition API 스타일의 조합이 좋았다. 프레임워크가 강제하는 것이 아무것도 없는 느낌이었다.
스캐폴딩 & 빌드 도구, Vite/빗
Vite/빗이 기존 웹팩 기반의 Vue CLI를 대치
Vue 저자인 Evan You가 만듬
Go랭으로 만들었으며 Vue CLI 대비 처리 속도가 압도적
2022-11-07 선택: Vite/빗 을 쓰자 - Vue CLI를 고집할 이유가 없다
2023-02-12 회고: 일단 Vue3를 선택했다면 Vite/빗을 쓰지 않을 이유가 없다. 웹팩을 쓸 때도 속도가 아쉬웠던 적은 없었지만, 확실히 Vite/빗이 더 빨랐다.
테스팅 도구, Vitest/빗테스트
Vitest/빗테스트가 기존 Jest를 대치
Vitest/빗테스트는...
처음부터 빌드도구 Vite/빗를 염두에 두고 개발
Jest와 유사, 기존 Jest 테스트 코드를 쉽게 마이그레이션 할 수 있음
Vue 코어팀이 만듬
테스트 코드 실행 속도가 빠름
2022-11-07 선택: Vitest/빗테스트를 쓰자 - 빌드도구로 Vite/빗을 쓸 거라면 당연한 선택
2023-02-12 회고: Vitest/빗테스트도 만족스러웠다. 사용법이 Jest와 거의 동일했다. 유닛테스트 실행 속도는 체감할 수 있을 정도로 빨랐다.
상태 관리 플러그인, Pinia/피냐
Pinia/피냐가 기존 Vuex를 대치
Vuex가 없어지는 것은 아님
Piania는 Vuex와 같은 혈통 (Vuex5에서 Vuex가 Pinia와 합쳐질 수도 있다)
Vue 저자 Evan You가 Vuex5와 Pinia/피냐는 사실상 같은 프로젝트라고 언급
Pinia/피냐의 특징
타입스크립트를 더 잘 지원
mutation을 제거, vuex 보다 간결해진 문법
Composition API 스타일을 지원
2022-11-07 선택: Pinia/피냐를 쓰자 - 지금 안 배우면 언제 배울까?
2023-02-12 회고: Vue 개발팀의 공식 프로젝트 다운 신뢰감을 느꼈다. Pinia를 Composition API 스타일로 사용했다. Vuex와 사용법이 달라 학습이 필요했는데, 대부분 Composition API 스타일에서 기인한 것이었다. Pinia를 Options API 스타일로 사용했다면 아무런 차이점도 느끼지 못했을 것 같다. Pinia가 Vuex를 계승하고, 차후 Vuex를 통합할 것이라는 얘기가 자연스럽게 이해됐다.
UI 라이브러리, Vuetify
Vue를 위한 UI 라이브러리로 Quasar와 Vuetify가 많이 쓰임
Quasar는 다양한 장치를 지원해야 할 때 좋은 선택
Vuetify는 UI 디자인에 투입할 자원이 없을 때 좋은 선택
2022-11-07 선택: Vuetify를 쓰자 - 버텨줘서 고맙다
2023-02-12 회고: 3달 전 Vue3 프로젝트를 시작하고 나서야 Vue3를 지원하는 Vuetify가 개발 중인 것을 알았다. 나는 방황하고 좌절했지만 이젠 Vuetify3를 선택해서 Vue3 프로젝트를 진행해도 좋을 것 같다 (얼마 전 Vuetify3가 릴리즈됐다).
트위터를 즐겨 쓴다. 나름 헤비 유저다. 트위터는 옛날부터 키보드 사용자를 배려해왔다. 트위터 화면에서 J,K 키를 입력하면 화면을 아래,위로 스크롤할 수 있다. VIM 사용자 입장에서 아주 자연스럽고 쾌적하다. 그런데 가끔 딱 시야를 방해하는 그 자리에 "새 트윗 보기" 팝업이 뜬다. 일단 팝업이 뜨면 가독성이 현격히 떨어진다. 쾌적하지 못하다.
그림 : 문제 현상
해결책을 찾기 위해 노력했다. 브라우저 개발자 도구를 열고 범인을 찾았다. 그리고 해당 html 요소를 투명하게 만들면 해결 가능함을 확인했다. 하지만 트위터를 켤 때마다 개발자 도구를 열고 콘솔창에서 "화면 청소 코드"를 실행시키는 것은 사람이 할 짓이 아니었다. 이런 건 분명 기계에게 시켜야 옳은 일이다. 그리고 나만 불편할까? 이 기능을 브라우저 애드온으로 만들어 공개한다면 널리 세상을 이롭게 하는, 단군 할아버지께서 기뻐하실 만한 일이 되지 않을까?
그림 : 범인
해결책 : 트위터 화면 청소 코드
obj = document.getElementsByClassName('r-dkhcqf'); for (o of obj) { o.style.opacity = 0.1 }
참조 코드를 찾자
모방은 창조의 어머니. 가장 먼저 할 일은 참조 코드를 찾는 일이다. 파이어폭스를 주력 브라우저로 쓰는 입장에서 아주 그럴듯한 참조 코드를 찾았다.webextensions-examples. 이름처럼 다양한 애드온 샘플로 구성된 프로젝트다. 제시된 애드온 샘플 중에서 borderify 샘플이 내게 잘 맞는다고 생각했다. borderify 애드온은 *.mozilla.org 페이지를 표시할 때마다 붉은색 테두리를 덧붙여 표시하는 애드온이다. 특정 url에 반응한다는 점(즉 트위터 url에 반응하는 애드온을 만들 수 있다는 점)과 브라우저 컨텐트를 대상으로 스크립트를 실행한다는 점(즉 트위터 화면 청소 코드를 실행시키는 애드온을 만들 수 있다는 점)이 내가 원하던 바였다.
파이어폭스 주소창에서 about:debugging을 입력하고, "임시 부가 기능 로드..." 버튼을 선택해서 manifest.json 파일을 선택하면, 브라우저에서 애드온을 실행시켜 볼 수 있다. 그렇게 애드온이 정상 동작함을 확인했다.
그림 : 애드온 개발 설정
이제 개발한 애드온을 정식 등록할 차례다. 그러면 브라우저를 실행시킬 때마다 "임시 부가 기능 로드..." 버튼을 클릭하지 않아도 된다. 그리고 집에 있는 컴퓨터 뿐 아니라 회사에 있는 컴퓨터에서도 이 애드온을 사용할 수 있게 된다. 절차는 간단했다.AMO 개발자 허브에 등록하면 된다. 소스 코드를 zip 파일로 압축해서 클릭 몇 번만 하면 등록이 완료된다. 그러면 24 시간 이내에 처리 결과를 알려주겠다는 친절한 메일이 온다. 그리고 정말 그 다음날 애드온이 등록됐다.
그림 : AMO에 정식 등록된 애드온
그림 : 파이어폭스에 정식 설치된 애드온
브라우저 애드온은 나름 표준 웹기술이어서 파이어폭스 애드온을 조금만 다듬으면 크롬 브라우저에서도 사용 가능하다. 크롬 브라우저를 위한 나머지 일은 다른 훌륭한 사람에게 미룬다. 브라우저로 할 수 있는 재미난 일이 더욱 많아지기를 희망한다.웹3 세상의 주력 플랫폼은 브라우저일 것이다.
미미하게 구글링 건수가 많고 (37,000건 vs 1,800건), grafana 대시보드가 멋진 k6를 선택
k6 프로젝트의 오너가 grafana-labs라서 grafana와의 연계가 좋을 수 밖에 없음
이런 멋진 대시보드를 실시간으로 볼 수 있음
사용법
k6를 실행하려면 influxDB와 grafana가 있어야 함
k6 + influxDB + grafana를 컨테이너로 실행하는 것이 가장 간편
k6 소스레포에서 docker-compose.yml 파일을 제공함
git clone https://github.com/grafana/k6 && cd k6
git submodule update --init
docker-compose up -d influxdb grafana
docker-compose run -v $PWD:/scripts k6 run /scripts/myscript.js
테스트 스크립트 작성
k6 자체는 go 언어로 작성됨
k6에서 실행되는 테스트 스크립트는 JavaScript로 작성함
테스트 스크립트는 반드시 default function을 export 해야 함
해당 function을 k6가 생성하는 VU(virtual user)들이 실행함
import http from "k6/http";
export default function() {
let response = http.get("https://test-api.k6.io");
};
실행 팁
grafana 커뮤니티에서 만든 대시보드들 중 4411 추천
k6 성능테스트 도중 "The flush operation took higher than the expected set push interval" 에러를 만남 ==> influxDB에 테스트 지표를 write 하는 시간이 지연되어 발생하는 에러 ==> 테스트 결과 분석에 필요한 지표만 SystemTags로 지정해서 influxDB의 지표 수집 부담을 줄여준다
- 컴포넌트 . 통상 웹UI 컴포넌트 하나를 구현하려면 html, css, js 3개 파일이 필요 . Vue는 UI 컴포넌트 하나를 하나의 파일로 정의 (SFC: Single File Component) . 개발/관리 측면에서 좋았음 - 급격하지 않은 변화 . 개발 진행중에 Vuetify 문서가 버전업됨 . 하지만 변화 폭이 크지 않아서 쉽게 적응할 수 있었음 . Vue 프레임워크 자체도 곧 3.0으로 버전업될 예정. 하지만 Vue 2.0과 크게 다르지 않을 예정 . "변화 폭이 크지 않고, 변화 방향이 합리적"인 것이 프레임워크의 중요한 장점이라 생각함
디버깅툴: Firefox + Vue Dev-tools 좋다
- Vue dev-tools의 vuex 히스토리 기능이 큰 도움 됨 어플리케이션의 상태 정보를 확인해서 해결되는 문제가 (생각보다) 많았음 - vuex의 mutation은 존재 의미를 불신하던 기능 (필요 없다 생각했음) Vue dev-tools 활용만으로도 vuex mutation의 가치를 느낌
프론트엔드 TDD: 정말 유용한가?
- 백엔드 tool을 개발하면서 TDD의 유용성을 체감함 - 그래서 프론트엔드 개발에도 TDD를 적용하는 것이 도리일 것이라고 생각, 이번 작업에서 프론트엔드 TDD를 시도해봄 - 구현 코드보다 테스트 코드를 먼저 작성하면서 개발 요구사항을 정리해봄 생각을 정리한다는 측면에서 나름 의미는 있었지만, - 프론트엔드 테스트 코드는 구현 코드와 밀결합될 수 밖에 없음을 느낌 그리고 프론트엔드의 문제점은 테스트 코드보다 눈과 손으로 먼저 체크하게 됨을 느낌 - 테스트 코드를 작성하는 번거로움 대비 실익을 느낄 수 없었음 - 단기간(3달) 동안 거의 혼자 하는 개발이어서 그랬을지도 모름. 베스트프랙틱스에 대한 조언을 구함
(이상)
2021-04-25.
HTML 태그의 data- 속성을 이용해서 실제 구현 코드와 테스트 코드의 의존성을 분리할 수 있다는 조언을 들었다.
예를 들어 화면에 표시되는 메시지 문자열을 검증하는 테스트 코드를 만들 경우, 특별한 data- 속성 (예를 들어 data-test-id="message")을 가진 HTML 요소를 찾아 그 문자열을 검증하면 된다. 이렇게 하면 개발자가 해당 문자열을 표현하기 위해 어떤 HTML 태그를 쓰는지, 어떤 id를 쓰는지 같은 세세한 구현 디테일과 분리된 테스트 코드를 작성할 수 있다. 그러면 차후 HTML 구조가 바뀌거나 엘리먼트 id가 바뀌어도 테스트 코드는 변경 없이 유지할 수 있다.
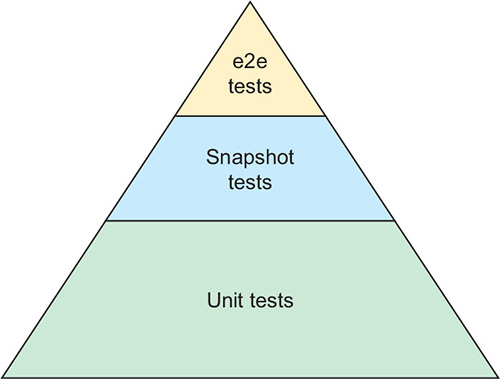
TDD를 시작하면서 잘 해보려는 의욕 때문에 테스트 케이스를 가능한 많이 작성하려 했다. 특히 HTML 요소들이 화면에 제대로 표시되는지까지 유닛 테스트로 확인하려 했다. 이 책 덕분에 그러면 안된다는 것을 알게 됐다 (테스트 케이스는 가능한 적게 작성해야 하고, 화면 출력에 관한 테스트는 스냅샷 테스트로 커버해야 한다는 것을 알게 됐다).